网络瓶颈该如何优化
整理文档事后翻到这篇文章 # Case study: Network bottlenecks on a Linux server,继而深入研究了一下 # Ring Buffer, 终于理解了之前遇到的一些词汇。本文将以 “how-to” 形式来指引,当出现网络瓶颈,该怎么进行调优。
0. 网络瓶颈场景
- 数据包处理数(QPS) 变成了直线
- cpu负载起飞,softirq占用比率异常高

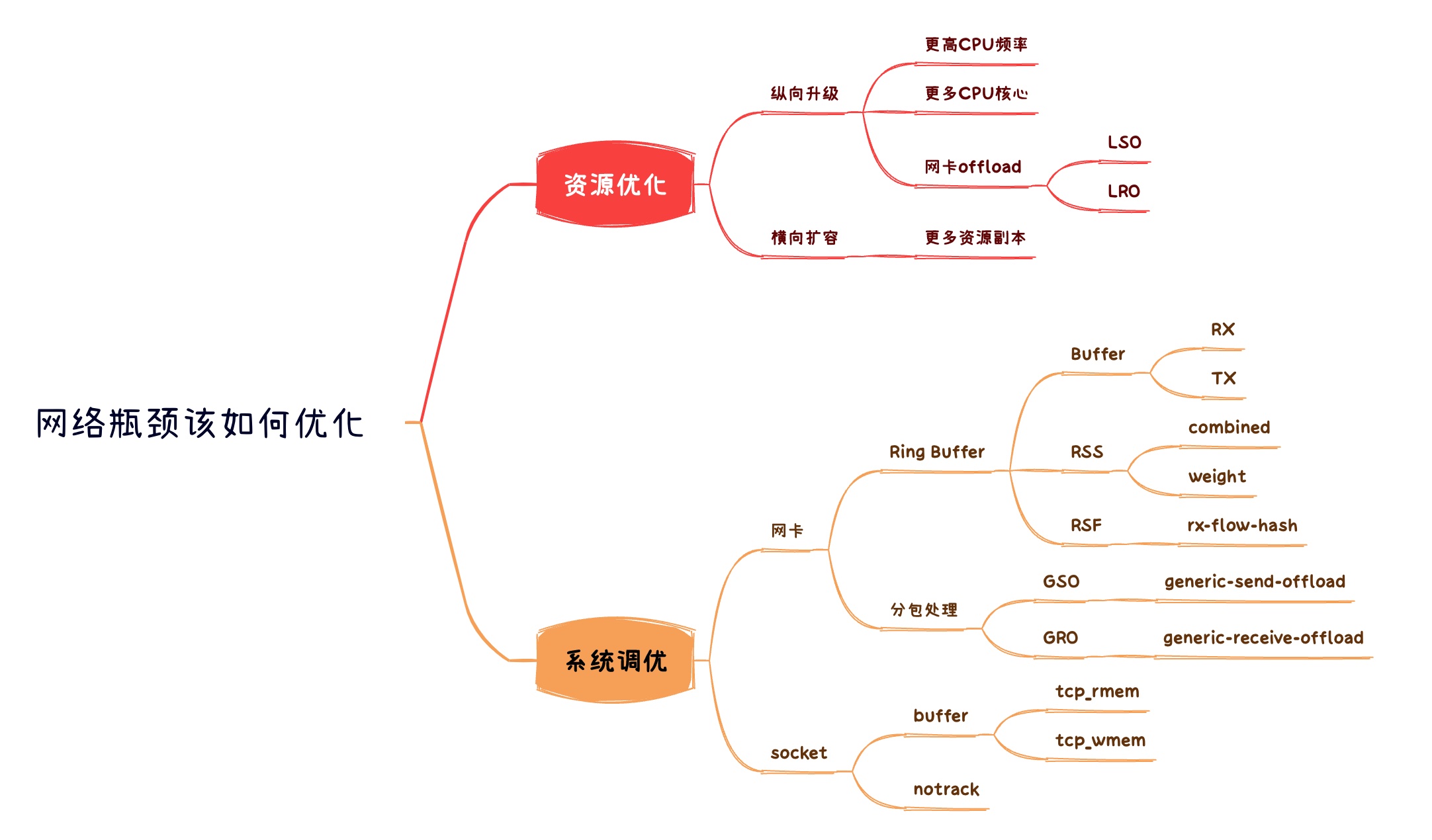
1. 优化指南
应急最有效办法:加钱升级(纵向升级)、加机器(横向扩展); 但如果你的基础设施还不足以支撑扩容,那么可以继续看配置优化
当系统CPU无法处理数据包,那么我们可以从2个方面进行评估
- 网卡配置优化:做多点 (Ring-buffer, offload)
- Ring-Buffer, RSS, RPS, RPS 配置
- 分包合并, LRO/LSO/GRO/GSO 配置
- 内核参数优化:缓存控制、连接处理 (Socket, CT)
- socket buffer
- notrack
1.1 网卡配置优化
涉及网卡配置主要有
- Ring Buffer
- 分包合并
Ring Buffer
指标观测
ethtool -S eh0
NIC statistics:
tx_packets: 51181015
rx_packets: 541783333
tx_errors: 0
rx_errors: 0
rx_missed: 559
align_errors: 0
...
- 通过 rx_fifo_errors 看到 Ring Buffer 上是否有丢包
队列缓存 (Buffer)
- 查看
ethtool -g eth0
- 修改
ethtool -G eth0 rx 4096ethtool -G eth0 tx 4096
队列数量 (RSS)
- 查看
$ethtool -l eth0
Channel parameters for eth0:
Pre-set maximums:
RX: n/a
TX: n/a
Other: 1
Combined: 4 # 最大值
Current hardware settings:
RX: n/a
TX: n/a
Other: 1
Combined: 1 # 看这个数值
- 修改
ethtool -L eth0 combined 4
队列权重 (RSS)
多CPU队列处理权重
- 查看
ethtool -x eth0
- 修改
ethtool -X eth0 weight * * * *
哈希规则 (RFS)
数据包如何哈希到多CPU队列上
- 查看
- TCP:
ethtool -n eth0 rx-flow-hash tcp4 - UDP:
ethtool -n eth0 rx-flow-hash udp4 - 其他协议:
ah4|esp4|sctp4|tcp6|udp6|ah6|esp6|sctp6
- TCP:
- 修改
ethtool -N eth0 rx-flow-hash udp4 sdfn
| key | desc |
|---|---|
| m | Hash on the Layer 2 destination address of the rx packet. |
| v | Hash on the VLAN tag of the rx packet. |
| t | Hash on the Layer 3 protocol field of the rx packet. |
| s | Hash on the IP source address of the rx packet. |
| d | Hash on the IP destination address of the rx packet. |
| f | (Source port) Hash on bytes 0 and 1 of the Layer 4 header of the rx packet. |
| n | (Destination port) Hash on bytes 2 and 3 of the Layer 4 header of the rx packet. |
| r | Discard all packets of this flow type. When this option is set, all other options are ignored. |
udp 由于无连接要求,sport并不需要固定相同,所以可以考虑用 sdn /sd 规则 (根据业务具体情况来设定)
分包合并
LRO/LSO/GRO/GSO
- 查看
ethtool -k eth0 | grep generic-receive-offload
- 开启
ethtool -K eth0 lro on
ethtool -K eth0 gro on
开启可能会影响应用,例如lvs,LVS内核模块在处理>MTU的数据包时,会丢弃。
- 关闭
ethtool -K eth0 lro off
ethtool -K eth0 gro off
1.2 内核参数优化
涉及内核参数有
- socket buffer
- notrack
指标观测
netstat -s | egrep "(collapse|prune)"
12 packets pruned from receive queue because of socket buffer overrun
# DEBIAN: apt install net-tools
socket buffer
- 查看
# sysctl -a | egrep "tcp_(r|w)mem"
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 87380 16777216
- 修改
sysctl -w "net.ipv4.tcp_rmem=4096 1048576 4194304"
注意,缓存越大受到GC影响越大,根据业务场景来设定。推荐4MB
notrack
nft add rule my_table prerouting tcp dport { 80, 443 } notrack
推荐在 raw.prerouting 中处理
3. 附录:名词参考
- softirq
- 软中断。数据包从网卡到应用需要给 CPU 发送一个中断处理请求,因此在大带宽的网络场景中,往往伴随着高的 softirq使用。这是正常,但在多CPU的设备上需要注意CPU的使用是否均衡,避免出现单核跑爆的情况。
- RSS
- Receive Side Scaling
- 支持 RSS 的网卡内部会有多个 Ring Buffer,NIC 收到 Frame 的时候能通过 Hash Function 来决定 Frame 该放在哪个 Ring Buffer 上,触发的 IRQ 也可以通过操作系统或者手动配置 IRQ affinity 将 IRQ 分配到多个 CPU 上。这样 IRQ 能被不同的 CPU 处理,从而做到 Ring Buffer 上的数据也能被不同的 CPU 处理,从而提高数据的并行处理能力
- RPS
- Receive Packet Steering
- 是在 NIC 不支持 RSS 时候在软件中实现 RSS 类似功能的机制
- 任何 NIC 都能支持 RPS,但缺点是 NIC 收到数据后 DMA 将数据存入的还是一个 Ring Buffer,NIC 触发 IRQ 还是发到一个 CPU,还是由这一个 CPU 调用 driver 的
poll来将 Ring Buffer 的数据取出来
- RFS
- Receive Flow Steering
- 由于RPS是按照包(Pakcage)粒度来调度分配CPU的,这会出现一个 Flow 的数据包正在被 CPU1 处理,但下一个数据包被发到 CPU2。
- 因此,RFS是配合RPS来保证同一个 flow 的 packet 都会被路由到正在处理当前 Flow 数据的 CPU,从而提高 CPU cache 比率
- LRO
- Large receive offload
- 在收到多个数据包的时候将同一个 Flow 的多个数据包按照一定的规则合并起来交给上层处理,这样就能减少上层需要处理的数据包数量。
- 应用于TCP协议
- 也会增加接受延迟
- GRO
- Generic receive offload
- LRO的软件实现
- LSO
- Large send offload
- 是指上层可以直接将大数据直接塞给网卡处理TCP分包,降低上层的分包带来的CPU消耗
- TSO
- TCP segmentation offload
- TCP数据的分片卸载到硬件
- GSO
- generic segmentation offload
- 通用的数据的分片卸载到硬件
- CT
- Connection tracking, 一般是指netfilter提供的连接conntrack
- 在大请求的场景,开启conntrack会增加CPU消耗。但关闭也会影响一下系统功能,例如主动连接、NAT。可以根据业务场景,针对特定业务端口进行
notrack